
Notice
Recent Posts
Recent Comments
Link
반응형
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 메소드
- 생성자
- DBA
- 깃허브
- 서버
- 자바
- springboot
- SQLP
- SQL
- 인덱스
- Oracle
- 상속
- 친절한 SQL 튜닝
- 멀티쓰레드
- java
- socket
- db버퍼캐시
- 친절한 sql튜닝
- 클래스
- DB
- 백준
- 인스턴스
- Swing
- Spring
- 오라클
- 카카오코딩테스트
- 클라이언트
- 컬렉션프레임워크
- 인덱스 튜닝
- Undo
Archives
- Today
- Total
프리 정보 컨텐츠
친절한 SQL 튜닝 - 1장 SQL 처리 과정과 I/O 방식 본문
반응형
1장 SQL 처리 과정과 I/O
1.1 SQL 파싱과 최적화
- SQL 튜닝을 시작하기에 앞서 옵티마이저가 SQL을 어떻게 처리하는지, 서버 프로세스는 어떻게 읽고 저장하는지 살펴보자.
옵티마이저
- SQL 옵티마이저는 SQL쿼리를 최적하기 위해 최적의 실행 계획을 결정하며 아래와 같은 과정을 통해 이루어집니다. (네비게이션과 같은 역할을 해주는 최적의 실행 계획을 해주는 내부 엔진으로 기억하자)
- 쿼리 파싱 및 분석 : SQL문을 분석하고 파싱하여 내부 표현으로 변환하여 분석.
- 통계 정보 수집 : 테이블 및 인덱스 통계 정보 수집.
- 실행 계획 생성 : 테이블 및 인덱스 액세스 방법, 조인 순서, 조인 방법 포함 실행.
- 최적 실행 계획 선택 : 생성된 실행 계획 중에서 가장 효율적 선택함으로써 쿼리 실행 시간, 리소스 사용량 최소
서버 프로세스
- 클라이언트 연결 수립.
- SQL 쿼리 수신.
- 쿼리 실행
- 결과 반환
- 연결 종료
프로시저
- 프로시저 : 데이터베이스 내에서 미리 컴파일되어 저장된 하나 이상의 SQL문과 프로그래밍 논리를 가진 데이터베이스 객체입니다.
CREATE OR REPLACE PROCEDURE calculate_sum (
num1 IN NUMBER,
num2 IN NUMBER
)
IS
total NUMBER;
BEGIN
-- 입력된 두 숫자의 합을 계산합니다.
total := num1 + num2;
-- 결과를 출력합니다.
DBMS_OUTPUT.PUT_LINE('두 숫자의 합: ' || total);
END;
-- 호출방법
BEGIN
calculate_sum(10, 20);
END;- SQL은 Structured Query Language 의 줄임말이다. PL/SQL 처럼 절차적 프로그래밍 기능을 구현할 수 있는 확장 언어도 제공하지만, 기본적으로 구조적이고 집합적이고 선언적인 질의 언어이다.
- 결과적으로는 구조적, 집합적이지만 결과집합을 만드는 과정은 절차적일 수 밖에 없기 때문에 프로시저가 필요하다. 그런 프로시저를 만들어 내는 DBMS 내부 엔진이 바로 SQL 옵티마이저이다.
- DBMS 내부에서 프로시저를 작성하고 컴파일해서 실행 가능한 상태로 만드는 전 과정을 SQL 최적화라고 한다.
SQL최적화
- SQL 파싱
- SQL파서가 파싱을 진행. 파싱을 요약하면 아래와 같음.
- 파싱 트리 생성 : SQL 문의 구성요소를 분석하여 파싱 트리 생성
- Syntax 생성 : 문법적 오류 유무 확인
- Semantic 체크 : 의미상 오류 확인 (존재하지 않는 테이블 또는 컬럼 사용 유무 파악)
- SQL 최적화
- 옵티마이저가 수집한 시스템 및 통계정보를 바탕으로 다양한 실행경로를 생성 비교 후 효율적인 하나 선택
- 로우 소스 생성
- 실행경로를 실제 실행 가능한 코드, 프로시저 형태로 포맷팅 하는 단계
SQL옵티마이저
- SQL옵티마이저 : 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해주는 DBMS 핵심 엔진
- 쿼리를 수행하는 데 후보군이 될만한 실행계획 탐색
- 데이터 딕셔너리에 수집해 둔 통계를 이용하여 각 실행계획의 예상비용 선택
- 최저 비용을 나타내는 실행계획 선택
실행계획과 비용
- DBMS에는 SQL 실행경로 미리보기를 통해 SQL이 테이블을 스캔하는지 인덱스를 스캔하는지, 인덱스 스캔을 한다면 어떤 인덱스인지를 확인할 수 있다.
CREATE INDEX tt1_x01 ON tt1(NO, id);
CREATE INDEX tt1_x02 ON tt1(NO, id, name);
SELECT
*
FROM
tt1
WHERE
NO = 2
AND id = 9;
SELECT /*+ index(tt1 tt1_x02) */
*
FROM
tt1
WHERE
NO = 2
AND id = 9;
SELECT /*+ full(tt1) */
*
FROM
tt1
WHERE
NO = 2
AND id = 9;- 위와 같이 인덱스를 생성하였을 때 옵티마이저는 T_X01 인덱스를 선택했다. 선택한 근거는 무엇일까?
- tt1_x02 인덱스를 선택했을 때는 코스트가 2, full scan을 선택했을 때는 코스트가 20으로 선택한 근거가 비용임을 알 수 있다.
- 비용은 쿼리를 수행하는 동안 발생할 것으로 예상되는 I/O 횟수 또는 예상 소요시간을 표현한 값이다.
- 하지만 네비게이션과 동일하게 목적지에 도착하기까지 걸리는 시간은 예상보다 늦게 도착할 수도 일찍 도착하기도 한다.
- SQL 실행계획에 표시되는 Cost도 어디까지나 예상치이며 옵티마이저가 통계정보를 활용해서 계산해 낸 값이다.
/*+ INDEX(A A_X01) INDEX(B B_X01) */ -- 두 유효
/*+ INDEX(C), FULL(D)*/ -- 첫 번째 힌트만 유효
-- 스키마명 명시 X
SELECT /*+ FULL(SCOTT.EMP)*/ -- 무효
FROM EMP
-- FROM 절 옆에 ALIAS 사용 시 힌트에도 ALIAS 사용
SELECT /*+ FULL(EMP)*/
FROM EMP e- 옵티마이저가 제공해주는 힌트를 사용할 때는 위와 같은 주의사항들에 맞춰서 사용하자.
SELECT /*+ LEADING(A) USE_NL(B) INDEX(A (주문일자)) INDEX(B 고객_PK) */
A. 주문번호, A.주문금액, B.고객명, B.연락처, B.주소
FROM 주문 A, 고객 B
WHERE A.주문일자 = :ORD_DT
AND A.고객ID = B.고객ID- 옵티마이저의 작은 실수가 기업에 큰 손실을 끼치는 시스템 같은 경우 위와 같이 빈틈없는 힌트 기술을 통해 다른 방식을 선택하지 못하도록 기술해준다.
- 자주 사용하는 힌트 목록은 27P 참고
1.2 SQL 공유 및 재사용
- SQL 내부 최적화 과정을 알고나면 동시성이 높은 트랜잭션 처리 시스템에서 바인드 변수가 왜 중요한지 이해하자.
소프트파싱 vs 하드파싱
- SQL 파싱, 최적화, 로우 소스 생성 과정을 거쳐 생성한 내부 프로시저를 반복 재사용할 수 있도록 캐싱해 두는 메모리 공간을 라이브러리 캐시라고 한다.
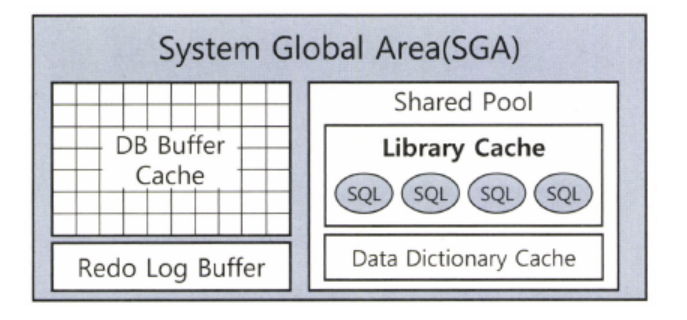
- 라이브러리 캐시는 위의 그림과 같은 구조이며 SGA구성요소이고, 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어 구조를 캐싱하는 메모리 공간이다.
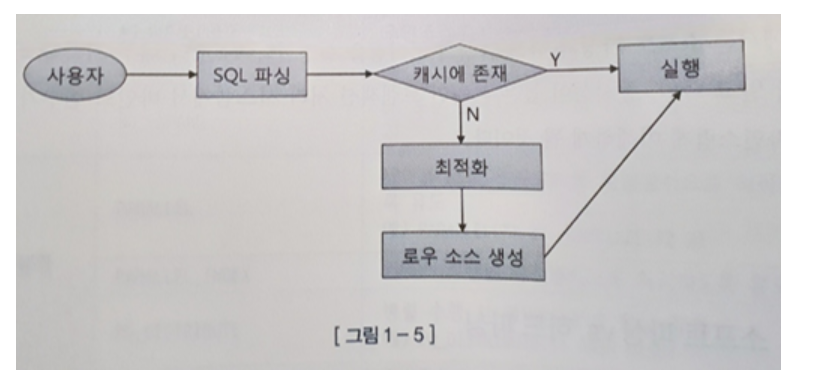
- 소프트 파싱과 하드 파싱은 위의 도식화한 그림으로 설명이 된다.
- 소프트파싱 : SQL을 캐시에서 찾아 바로 실행단계로 넘어가는 것
- 하드파싱 : 찾는 데 실패해 최적화 및 로우 소스 생성 단계까지 모두 거치는 것
SQL 최적화 과정은 왜 하드한가?
- 네비게이션을 예로 들어 가장 빠른 길을 선택하는 방식은 최적 경로 탐색이 꽤 어렵고 무거운 작업임을 알 수가 있다.
- 마찬가지로 옵티마이저 SQL을 최적할 때도 훨씬 많은 일을 수행한다.
- ex) 다섯 개 테이블 조인 쿼리문 5! 가지 수, NL, 소트 머지, 해시, 테이블 전체, 인덱스 스캔 등등.. 고려해야 할 일이 상당히 많다.
- 데이터베이스에서 이루어지는 처리 과정은 대부분 I/O 작업에 집중되는 반면, 하드 파싱은 CPU를 많이 소비하는 몇 안되는 작업 중 하나이다.
- 어려운 하드파싱 작업을 거쳐 생성한 내부 프로시저를 한 번만 사용하고 버린다면 이만저만한 비효율이기 때문에 라이브러리 캐시가 필요하다
1.2.1 바인드 변수의 중요성
- 사용자 정의 함수/프로시저, 트리거, 패키지 등은 생성할 때부터 이름을 갖는다.
- 컴파일 상태로 딕셔너리에 저장되며, 사용자가 삭제하지 않는 한 영구적으로 보관된다.
- 실행할 때 라이브러리 캐시에 적재함으로써 여러 사용자가 공유하면서 재사용한다.
이름없는 SQL문제
- 반면에 SQL은 이름이 따로 없기 때문에 딕셔너리에 저장하지 않으며, 처음 실행할 때 최적화 과정을 거쳐 동적으로 생성한 내부 프로시저를 라이브러리 캐시에 적재함으로써 재사용한다.
- 캐시 공간이 부족하게되면 버려졌다가 다음에 다시 실행할 떄 똑같은 과정을 거쳐 캐시에 적재된다.
- 라이브러리 캐시에서 SQL을 찾기 위해 사용하는 키 값이 SQL문 그 자체이므로 각각 최적화를 진행하고 라이브러리 캐시에서 별도 공간을 사용한다.
아래 중요한 예제를 통해 알아보자
- 500만 고객을 보유한 어떤 쇼핑몰에서 로그인 모듈 담당 개발자가 프로그램을 아래와 같이 작성했다고 하자.
public void login(String login_id) throws Exception{
String SQLStmt = "SELECT * FROM CUSTOMER WHERE LOGIN_ID = '" + login_id + "'";
Statement st = con.createStatement();
ResultSet rs = st.executeQuery(SQLStmt);
if(rs.next()){
// do anything
}
rs.close();
st.close();
}- 위와 같이 코드를 작성할 경우 100만 고객이 동시에 시스템 접속을 하면 무슨 일이 발생할까?
- DBMS에 발생하는 부하는 대게 과도한 I/O가 원인이기 때문에 여러 종류의 경합 떄문에 로그인 처리가 제대로 처리되지 않을 것이다.
- 이유는 SQL 하드파싱 때문이다. 내부 라이브러리 캐시(V$SQL)를 조회해보자.
SELECT * FROM CUSTOMER WHERE LOGIN_ID = 'oraking'
SELECT * FROM CUSTOMER WHERE LOGIN_ID = 'javaking'
SELECT * FROM CUSTOMER WHERE LOGIN_ID = 'tommy'
...
...
-- 내부 프로시저
create procedure LOGIN_ORAKING() {...}
create procedure LOGIN_JAVAKING() {...}
create procedure LOGIN_TOMMY() {...}
...
...- 로그인 프로그램을 이렇게 작성하게 되면 고객이 로그인할 때마다 DBMS 내부 프로시저를 하나씩 만들어서 라이브러리 캐시에 적재하는 셈이다.
- 이런식으로 여러 개 생성할 것이 아니라 로그인ID를 파라미터로 받는 프로시저 하나를 공유하면서 재사용 하는 것이 유리하다.
-- 로그인 ID를 파라미터로 받는 프로시저를 하나로 공유한다면?
create procedure LOGIN (login_id in varchar2) {...}
public void login(String login_id) throws Exception{
String SQLStmt = "SELECT * FROM CUSTOMER WHERE LOGIN_ID = ?";
PreparedStatement st = con.prepareStatement(SQLStmt);
st.setString(1, login_id);
ResultSet rs = st.executeQuery();
if(rs.next()){
// do anything
}
rs.close();
st.close();
}
-- 아래와 같은 로그인과 관련해서 아래 SQL 하나만 발견된다.
SELECT * FROM CUSTOMER WHERE LOGIN_ID = :1- 이처럼 파라미터 Driven 방식으로 SQL을 작성하는 방법이 제공되는데 이 것이 바로 바인드 변수이다.
- 종합해보자면 하드파싱은 하나만 사용함으로써 캐싱된 SQL을 100만 고객이 공유하고 재사용함으로써 부담을 줄이는 것이다.
1.3 데이터 저장 구조 및 I/O 메커니즘
- I/O 튜닝이 곧 SQL 튜닝이라고 해도 과언이 아닐만큼 I/O 이해에 대한 이해가 중요할 수 밖에 없다. 데이터 저장 구조, 디스크 및 메모리에서 데이터를 읽는 메커니즘을 제대로 살펴보자.
SQL이 느린이유
- SQL이 느린 이유는 십중팔구 I/O 때문이다. 구체적으로 디스크 I/O 때문이다.
- 그렇다면 I/O란 무엇일까 이 책의 저자는 I/O 를 잠(SLEEP) 이라고 설명한다.
- OS 또는 I/O 시스템이 처리하는 동안 프로세스는 잠을 자기 때문이다.
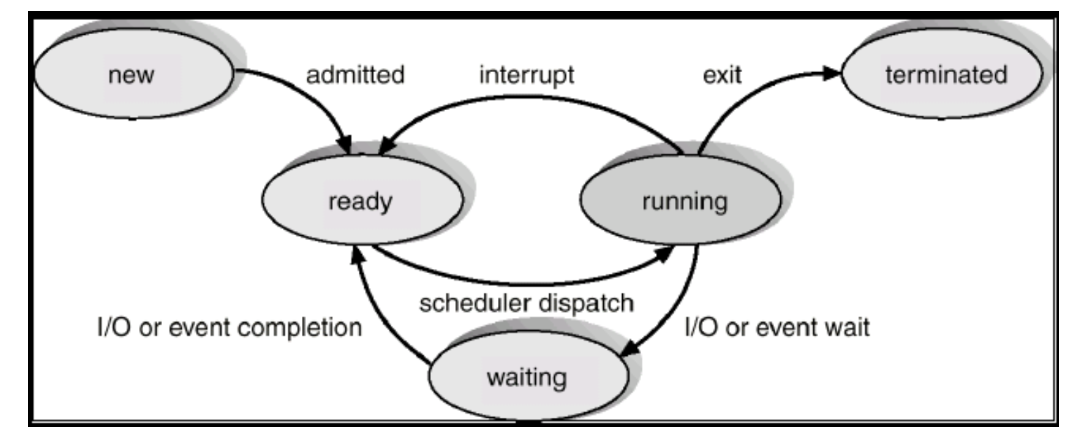
- 프로세스는 실행 중인 프로그램이며 위와 같은 생명주기를 같는다.
- 생성 이후 종료 전까지의 준비와 실행과 대기 상태를 반복한다.(new -> ready -> running -> wait -> terminated)
- 여러 프로세스가 하나의 CPU를 공유할 수 있지만 특정 순간에는 하나의 프로세스만 CPU를 사용할 수 있기 때문에 이런 메커니즘이 필요하다.
- interrupt 없이 일하는 프로세스도 디스크에서 데이터를 읽을 때는 CPU를 OS에 반환하고 수면상태에서 I/O가 완료되기를 기다린다.
- 열심히 일해야 할 프로세스가 잠을 자고 있으니 I/O가 많으면 성능이 느려질 수 밖에 없다.
- 일반적으로 I/O Call 속도는 Single Block I/O 기준 평균 10ms
1.3.1 데이터베이스 저장 구조
- 데이터를 저장하려면 먼저 테이블스페이스를 생성해야 한다.
- 테이블스페이스는 세그먼트를 담는 콘테이너로서, 여러 개의 데이터파일로 구성된다.
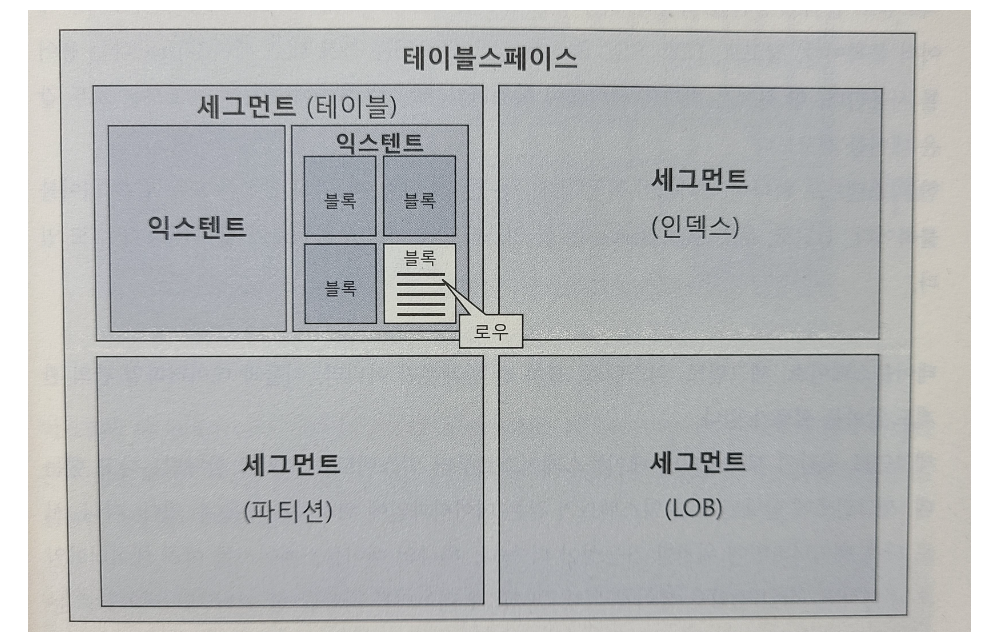
- 위와 같이 테이블스페이스를 생성했으면 그림처럼 세그먼트(테이블, 저장공간이 필요한 오브젝트)를 생성한다.
- 세그먼트는 여러 익스텐트로 구성되어있다. 파티션 구조가 아니라면 테이블도 하나의 세그먼트이고 인덱스도 하나의 세그먼트이다. (즉 각 파티션이 하나의 세그먼트)
- 익스텐트는 연속된 블록들의 집합이기도 하다. 연속된 여러 개의 데이터 블록으로 구성되어있다.
- 실제로 저장하는 공간은 데이트 블록이고 한 블록에 저장된 레코드는 모두 같은 테이블 레코드이다.
- 데이터베이스에서 데이터를 읽고 쓰는 단위는 블록이며, 특정 레코드 하나를 읽는다하더라도 해당 블록을 통째로 읽는다.
- 각 용어에 대해 간단히 정의하자면 아래와 같다.
- 블록 : 데이터를 읽고 쓰는 단위
- 익스텐트 : 공간을 확장하는 단위, 연속된 블록 집합
- 세그먼트 : 데이터 저장공간이 필요한 오브젝트
- 테이블스페이스 : 세그먼트를 담는 콘테이너
- 데이터파일 : 디스크 상의 물리적인 OS 파일
1.3.2 시퀀셜 액세스 vs 랜덤 엑세스
- 테이블 또는 인덱스 블록을 액세스하는 방식으로는 시퀀셜 액세스와 랜덤 액세스 두 가지가 있다.
- 시퀀셜 엑세스는 단어의 의미와 같이 연결된 순서에 따라 차례대로 블록을 읽는 방식이다.
- 인덱스 리프 블록은 앞뒤를 가리키는 주소값을 통해 논리적으로 연결되어있는데 이 주소 값에 따라 앞 또는 뒤로 순차적으로 스캔하는 방식이 시퀀셜 액세스에 해당한다.
데이터 블록 간에는 서로 논리적인 연결고리를 갖고 있지 않은데 어떻게 액세스할까?
- 오라클은 세그먼트에 할당된 익스텐트 목록을 세그먼트 헤더에 맵으로 관리한다.
- 익스텐트 맵은 각 인스텐트의 첫 번째 블록 주소 값을 갖는다.
- 읽어야 할 익스텐트 목록을 익스텐트 맵에서 얻고, 연속해서 저장된 블록을 순서대로 읽으면 이것이 Full Table Scan 이다.
- 랜덤 액세스는 논리적, 물리적인 순서를 따르지 않고, 레코드 하나를 읽기 위해 한 블록씩 접근하는 방식이다.
1.3.3 논리적I/O vs 물리적 I/O
DB 버퍼캐시
- 디스크 I/O가 SQL 성능을 결정하는 것은 거듭 강조한다.
- 자주 읽는 블록을 매번 디스크에서 읽는 것은 비효율적이고 DBMS에 데이터 캐싱 매커니즘이 필수인 이유이다.
- 앞서 알아본 라이브러리 캐시가 SQL과 실행계획, DB 저장형 함수/프로시저 등을 캐싱하는 코드 캐시라고 한다면, DB 버퍼 캐시는 데이터 캐시라고 할 수 있다(같은 블록에 대한 반복적인 I/O Call을 줄이는 목적)
- 서버 프로세스와 데이터 파일 사이에 위치함으로써 데이터 블록을 읽기 전에 버퍼캐시부터 탐색한다.
- 운 좋게 캐시에서 블록을 찾으면 프로세스가 잠을 자지 않아도 되니 속도는 당연히 빠르고, 찾지 못하더라도 한 번은 I/O Call을 하고 잠을 자겠지만 두 번째 부터는 잠을 자지 않아도 되는 공유메모리 영역으로 같은 블록을 읽는 다른 프로세스도 득을 본다.
논리적 I/O vs 물리적 I/O
- 논리적 블록 I/O : SQL문을 처리하는 과정에 메모리 버퍼캐시에서 발생한 총 블록 I/O (메모리 I/O)
- 물리적 블록 I/O : 디스크에서 발생한 총 블록 I/O (디스크 I/O)
- SQL 처리 도중 읽어야 할 블록을 버퍼캐시에서 찾지 못할 때만 디스크를 액세스하므로 논리적 블록 I/O 중 일부를 물리적으로 I/O 한다.
- 메모리 I/O는 전기적 신호인데 반해, 디스크 I/O는 액세스 암을 통해 물리적 작용이 일어나므로 논리적 I/O보다 10,000배쯤 느리다.
- SQL을 수행하려면 데이터가 담긴 블록을 읽어야 하는데 데이터를 입력하거나 삭제하지 않는 상황에서 조건절에 같은 변수 값을 입력하면, 아무리 여러 번 실행해도 매번 읽는 블록 수는 같다.
- SQL을 수행하면서 읽은 총 블록 I/O가 논리적 I/O이다.
- DB 버퍼캐시에서 블록을 찾지 못해 디스크에서 읽은 블록 I/O가 물리적 I/O 이다.
버퍼캐시 히트율
- 버퍼캐시 효율을 측정하는 데 전통적으로 가장 많이 사용해 온 지표는 버퍼캐시 히트율(BCHR)이다.
BCHR = (논리적 I/O - 물리적 I/O / 논리적 I/O) * 100
- BCHR은 읽은 전제 블록 중에서 물리적인 디스크 I/O를 수반하지 않고 곧바로 메모리에서 찾은 비율을 나타낸다.
- 일반적으로 시스템 레벨에서 평균 99% 히트율을 달성해야 한다.
- 실제 SQL 성능을 향상하려면 물리적 I/O 가 아닌 논리적 I/O를 줄여야 한다. 공식을 아래와 같이 변경하면 쉽게 알 수 있다.
물리적 I/O = 논리적 I/O * (100 - BCHR)
- 즉 논리적 I/O는 일정하여 물리적 I/O는 BCHR에 의해 결정되는데 시스템 상황에 의해 결정되기 때문에 SQL 성능을 높이기 위해서는 논리적 I/O를 줄이는 일뿐이다.
- 논리적 I/O를 줄임으로써 물리적 I/O를 줄이는 것이 곧 SQL 튜닝이다.
1.3.4 SingleBlock I/O vs MultiBlock I/O
- 메모리 캐시가 클수록 좋지만, 데이터를 모두 캐시에 적재할 수는 없으므로 캐시에서 찾지 못한 데이터 블록은 I/O Call을 통해 디스크에서 DB 버퍼캐시로 적재하고서 읽는다.
- I/O Call을 할 때, 한 번에 한 블록씩 요청하기도 하고, 여러 블록씩 요청하기도 하는데 한 번에 한블록씩 요청해서 메모리에 적재하는 방식을 Single Block I/O 라고한다.
- 반면에 한 번에 여러 블록씩 요청해서 메모리에 적재하는 방식을 Multiblock I/O 라고 한다.
- 인덱스를 이용할 때는 기본적으로 인덱스와 테이블 모두 Single Block I/O 방식을 사용한다.
- 반대로 많은 데이터 블록을 읽을 때는 Multiblock I/O 방식이 효율적이다(Full Scan).
- 정리하자면 MultiBlock I/O는 캐시에서 찾지 못한 특정 블록을 읽으려고 할 때 캐시에 미리 적재하는 기능이며 Full Scan 할 때 성능이 좋다.
1.3.5 Table Full Scan vs Index Range Scan
- 테이블에 저장된 데이터를 읽는 방식은 크게 두 가지다. 테이블 전체를 스캔해서 읽는 방식과 인덱스를 이용해서 읽는 방식이다.
- Tabls Full Scan 은 말그대로 테이블에 속한 블록 '전체'를 읽어서 사용자가 원하는 데이터를 찾는 방식이다.
- 인덱스를 이용한 테이블 액세스는 인덱스에서 일정량을 스캔하면서 얻은 ROWID로 테이블 레코드를 찾아가는 방식이다.
무조건적으로 Index Scan 을 사용하는 것이 빠르진 않다?
여지껏 무조건 Index Scan 을 타야 속도가 빠른 줄 알았는데 이 책에서는 그렇지 않다라고 정의하고 있다. 이유에 대해서 알아보자.
- Table Full Scan은 시퀀셜 액세스와 Multiblock I/O 방식으로 디스크 블록을 읽는다.한 블록에 속한 모든 레코드를 한 번에 읽어 들이고, 캐시에서 찾지 못하면 한 번의 수면을 통해 수십 ~ 수백 개 블록을 한꺼번에 I/O 하는 메커니즘이다.
- 하지만 수십 ~ 수백 건의 소량 데이터를 찾을 때 수백만 ~ 수천만 건 데이터를 스캔하는건 비효율적이므로 소량 데이터를 검색할 때는 반드시 인덱스를 이용해야 한다.
- Index Range Scan을 통한 테이블 액세스는 랜덤 액세스와 Single Block I/O 방식으로 디스크 블록을 읽는다. 캐시에서 블록을 못찾으면, '레코드 하나를 읽기 위해 매번 잠을 자는 I/O 메커니즘이다. 따라서 많은 데이터를 읽을 때는 Table Full Scan보다 불리하다.
반응형
'SQLP/친절한 SQL 튜닝' Related Articles
more



Comments