
- 분류 전체보기 (85)

Notice
Recent Posts
Recent Comments
Link
반응형
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- socket
- 코딩
- 멀티쓰레드
- Oracle
- 깃허브
- DB
- 친절한 sql튜닝
- 백준
- 컬렉션프레임워크
- 친절한 SQL 튜닝
- 자바
- 인스턴스
- 카카오코딩테스트
- 서버
- 생성자
- 클라이언트
- 인덱스 튜닝
- 클래스
- SQL
- springboot
- 메소드
- 상속
- DBA
- java
- JavaScript
- SQLP
- Spring
- Swing
- db버퍼캐시
- 오라클
Archives
- Today
- Total
프리 정보 컨텐츠
친절한 SQL 튜닝 - 5장 소트 튜닝 본문
반응형
5장 소트 튜닝

- 소트할 대상 집합을 SGA 버퍼캐시를 통해 읽어 Sort Area에서 정렬을 시도한다.
- Sort Area안에서 정렬을 마무리하는 것이 최적이지만, 양이 많을 때는 Temp 테이블 스페이스에 임시 세그먼트를 만들어 저장한다. Sort Area가 찰 때마다 Temp 영역에 저장해 둔 중간 단계의 집합을 Sort Run 이라고 부르며 정렬된 최종 결과집합을 얻으려면 다시 Merge 해야 한다.
- 소트 연산은 메모리 집약적일 뿐 아니라 CPU 집약적이기도 하여 데이터량이 많으면 I/O 까지 발생하여 쿼리 성능을 좌우하는 중요한 요소이다.
부분범위 처리를 불가능하게 함으로써 OLTP 환경에서 애플리케이션 성능을 저하시키는 주요인이 되기도 한다.
5.1.2 소트 오퍼레이션
Sort Aggregate
- Sort Aggregate는 전체 로우를 대상으로 집계를 수행할 때 나타난다. Sort 라는 표현을 사용하지만
실제로는 데이터를 정렬하지는 않으며 Sort Area를 사용한다는 의미로 이해하면 된다. - 각각의 집계함수에 NULL이 아닌 레코드를 만나면 COUNT 변수에 담아 1씩 증가시킨다.
Sort Order By
- 데이터를 정렬할 때 나타나는 실행 계획
Sort Group By
- 그룹별 집계를 수행할 때 나타나는 실행 계획

- Group By 부서번호로 틀을 만들어 정보를 읽으면서 변수들의 Aggregate 를 수행하고 갱신하여 결과값을 출력한다.
- 부서(그룹 개수)가 많지 않다면 Sort Area가 클 필요가 없으며 이는 Temp 테이블스페이스를 쓰지 않는다는 것이다.
- Group by 절 뒤에 Order By 절을 명시하지 않으면 Hash Group By 방식으로 처리된다.
Sort Unique
- 옵티마이저가 서브쿼리를 풀어 일반 조인문으로 변환하는 것을 서브쿼리 Unnesting 이라고 한다.
- Unnesting된 서브쿼리가 조인 컬럼에 Unique 인덱스가 없을 때 M쪽 집합이면 조인하기전에 중복 레코드부터 제거하는데 이 때 Sort Unique 오퍼레이션이 나타난다.
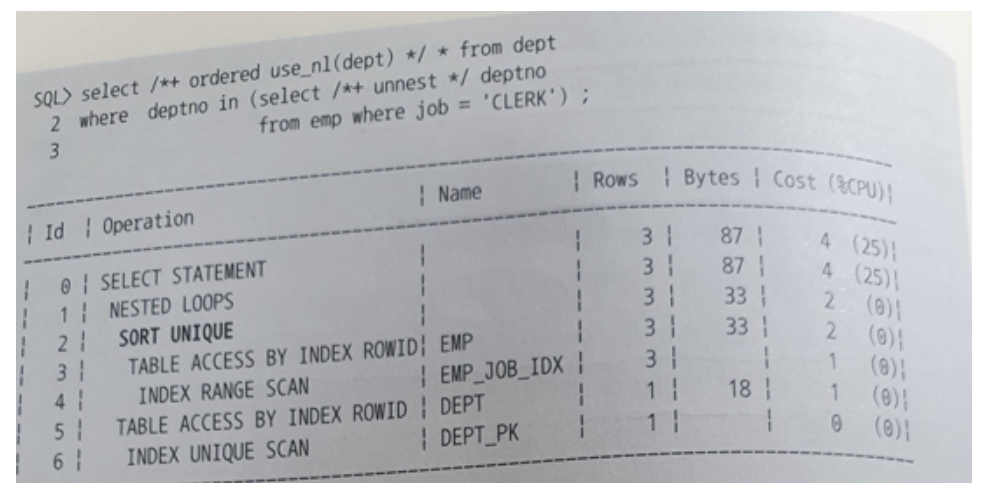
- 만약 PK/Unique 제약 또는 Unique 인덱스를 통해 서브쿼리의 유일성이 보장된다면, Sort Unique 오퍼레이션은 생략된다.
- Union, Minus, Intersect 같은 집합 연산자를 사용할 때도 Sort Unique 오퍼레이션이 나타난다.
- Distinct 연산에도 Sort Unique 오퍼레이션이 나타나지만 오라클 10gR2 부터는 Distinct 연산에는 Hash Unique 방식을 사용한다.
Sort Join
- Sort Join 오퍼레이션은 소트 머지 조인을 수행할 때 나타난다.
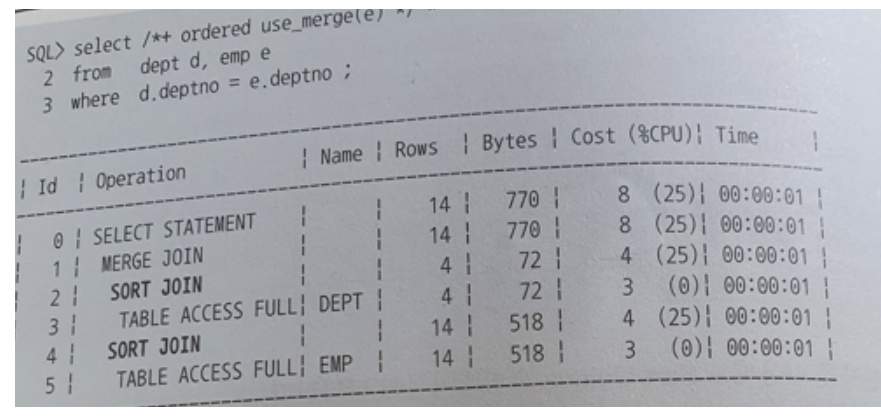
5.2 소트가 발생하지 않도록 SQL 작성
Union, Minus, Distinct 연산자는 중복 레코드를 제거하기위한 소트 연산을 발생하므로 꼭 필요한 경우에만 사용해야한다.
5.2.1 Union vs Union All
- SQL에 Union을 사용하면 상단과 하단 두 집합 간 중복을 제거하려고 소트 작업을 수행한다.
- 반면 Union All 은 중복을 확인하지 않고 단순히 결합하므로 소트 작업을 수행하지는 않는다. (될 수 있으면 Union All을 사용해야하는 이유)

- 위의 쿼리는 결제수단코드가 달라 중복 가능성이 없음에도 불구하고 UNION 을 사용하고 있다. 이렇게 되면 소트 연산이 발생함으로 성능을 위해 UNION ALL 을 사용하는 것이 좋다.

- 위에 쿼리는 인스턴스 중복 가능성이 있는 쿼리이다. 이 같은 경우에 UNION ALL 을 사용하게 되면 같은 결제 데이터가 중복해서 나오게 된다. 이 같은 경우는 소트 연산이 발생하지 않으면서 UNION ALL 을 사용해야하므로 쿼리를 아래와 같이 변환해야한다.

5.2.2 Exists 활용
- 중복 레코드를 제거할 목적으로 Distinct 연산자를 종종 사용하는데, 이는 조건에 해당하는 데이터를 모두 읽어서 중복을 제거한다. 이렇게 되면 부분범위 처리는 불가하고, 이 과정에 많은 I/O가 발생한다.
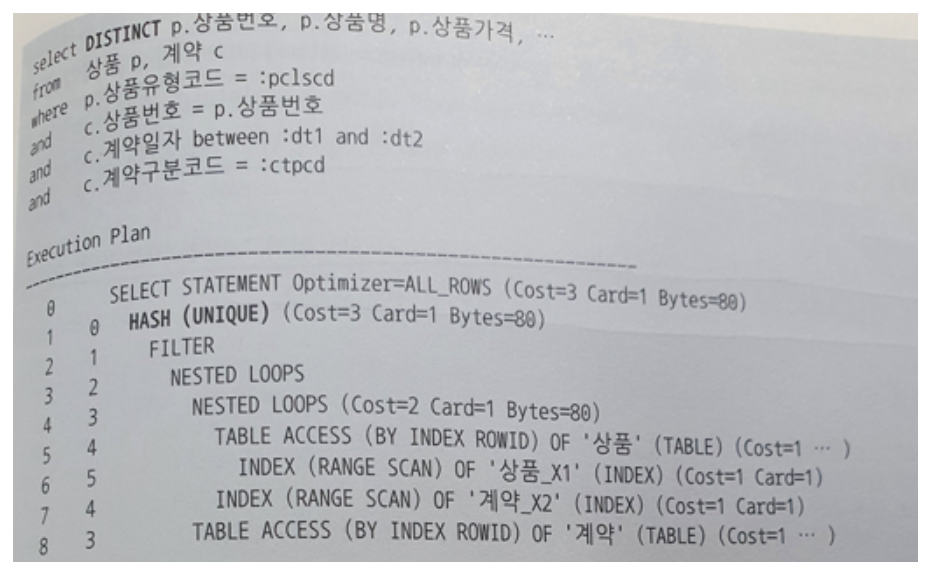
- 위에 쿼리는 상품유형코드 조건절에 해당하는 상품에 대해 계약일자 조건 기간에 발생한 계약 데이터를 모두 읽는 비효율이 존재한다. 상품 수는 적고 계약 건수가 많을 수록 비효율이 큰 패턴이다. 이를 Exists 를 이용하여 튜닝하면 아래와 같다.

- Exists 서브쿼리는 데이터 존재 여부만 확인하면 되기 때문에 조건절을 만족하는 데이터를 모두 읽지 않는다.
상품유형코드 조건절에 해당하는 상품에 대해 계약일자 조건 기간에 발생한 계약 중 계약구분코드 조건절을 만족하는 데이터가 한건이라도 존재하는지만 확인한다.- Distinct 연산자를 사용하지 않았으므로 상품 테이블에 대한 부분범위 처리도 가능하다.
- Minus 연산자를 Exists 서브쿼리로 변환하는 경우는 아래와 같이 변환한다.

- 계약_X01 인덱스가 지점id + 계약일시 순이면 소트 연산을 생략할 수 있지만, 해시 조인이기 때문에 Sort Order By 로 옵티마이저가 선택했다.
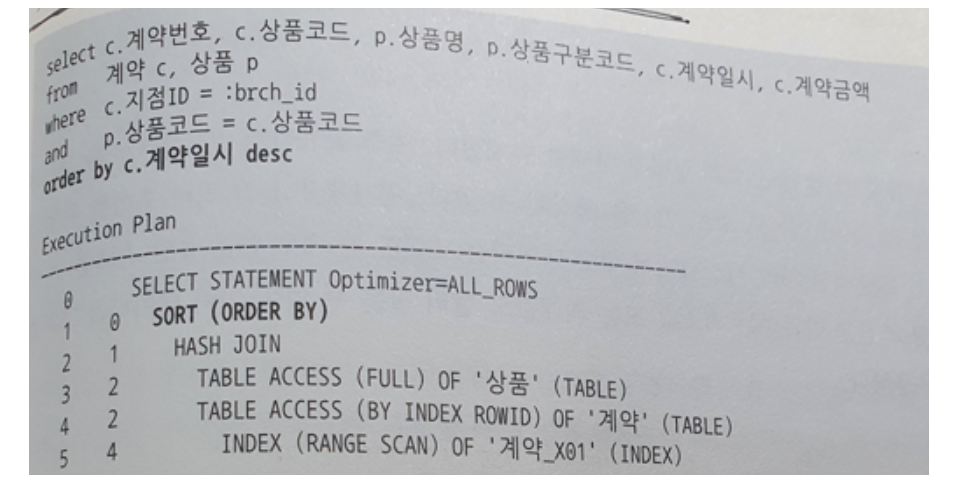
- 아래와 같이 계약 테이블을 기준으로 상품 테이블과 NL조인하도록 조인 방식을 변경하면 소트 연산을 생략할 수 있어 큰 성능 개선 효과를 얻을 수 있다.

- 정렬 기준이 조인 키 컬럼이면 소트 머지 조인도 Sort Order By 연산을 생략할 수 있다.
5.3 인덱스를 이용한 소트 연산 생략
- 인덱스는 항상 키 컬럼 순으로 정렬된 상태를 유지하므로 Order By 또는 Group By 절이 있어도 소트 연산을 생략할 수 있다.
5.3.1 Sort Order By 생략
- 인덱스 선두 컬럼을 [ 종목코드 + 거래일시 ] 순으로 구성하지 않으면 아래 쿼리에서 소트 연산을 생략할 수 없다.
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 종목거래
WHERE 종목코드 = 'KR123456'
ORDER BY 거래일시 - 종목코드 = 'KR123456' 조건을 만족하는 레코드를 인덱스에서 모두 읽어 많은 테이블 랜덤 액세스가 발생한다. 이 때 거래일시 순으로 정렬을 마치고 출력을 시작하므로 OLTP 환경에서 빠른 응답 속도를 내기는 어렵다.
부분범위 처리 활용 튜닝 기법
- 부분범위 처리는 쿼리 수행 결과 중 앞쪽 일부를 우선 전송하고 멈추었다가 클라이언트가 추가 전송을 요청할 때마다 남은 데이터를 조금씩 나눠 전송하는 방식을 말한다.
- 요즘 DB는
3-Tier 환경(클라이언트 프로그램이 DB에 직접 접속하는 2-Tier 환경이 아닌클라이언트와 DB 사이에 WAS, AP 서버 등이 존재하는 환경)으로 클라이언트가 특정 DB 커넥션을 독점할 수 없다. - 이 때 부분범위 처리 활용은 첫째, 결과집합 출력을 바로 시작할 수 있느냐, 둘째, 앞쪽 일부만 출력하고 멈출 수 있느냐가 핵심으로 3-Tier 환경에서는 의미 없다 생각할 수 있지만,
Top N 쿼리에 있어서 3-Tier 환경에서는 아직도 유효하다.Top N 쿼리에 대해서 알아보자.
5.3.2 Top N 쿼리
- Top N 쿼리는 전체 결과집합 중 상위 N개 레코드만 선택하는 쿼리이다.
SELECT * FROM (
SELECT 거래일시, 체결건수...
FROM 종목거래
WHERE 종목코드 = 'KR123456'
AND 거래일시 >= '20180304'
ORDER BY 거래일시
)
WHERE ROWNUM <= 10- 인라인 뷰로 정의한 집합을 모두 읽어 거래일시 순으로 정렬한 중간 집합을 우선적으로 만들고 상위 열 개 레코드를 취하는 형태이다.
- 위 쿼리에 [ 종목코드 + 거래일시 ] 순으로 구성된 인덱스를 사용하면 옵티마이저는 소트 연산을 생략하며 열 개 레코드를 읽는 순간 바로 멈춘다.
- 이는 조건절에 부합하는 레코드가 아무리 많아도 그 중 ROWNUM 으로 지정한 건수만큼 결과 레코드를 얻으면 거기서 바로 멈춘다는 뜻이며 이 기능을
Top N Stopkey알고리즘이라고 부른다.
페이징 처리
- 3-Tier 환경에서 대용량 결과집합을 조회할 때 부분 범위 처리는 페이징 처리를 사용한다.
- 일반적으로 사용하는 패턴을 알아보자.
SELECT *
FROM(
SELECT ROWNUM NO, A.*
FROM (
SELECT 거래일시, 체결건수...
FROM 종목거래
WHERE 종목코드 = 'KR123456'
AND 거래일시 >= '20180304'
ORDER BY 거래일시
) A
)
WHERE ROWNUM <= (:PAGE * 10)
)
WHERE NO >= (:PAGE - 1) * 10 + 1- Top N 쿼리로 ROWNUM 으로 지정한 건수만큼 결과 레코드를 얻으면 거기서 바로 멈춘다.
- 주로 카페 게시글 목록을 조회하거나 은행 사이트에서 입출금 내역을 조회할 때 1~2 페이지만 확인한다.
- 부분 범위 처리가 가능하도록 SQL을 작성한다는 의미는
인덱스 사용이 가능한 조건절, 조인은 NL조인 위주로 처리, 소트 연산을 생략할 수 있도록 인덱스를 구성하는 것이다.
반응형
'SQLP/친절한 SQL 튜닝' Related Articles
more



Comments